This figure depicts the classic Hindu myth of the blind men examining an elephant. To me, it also reflects the state of psychological science.
We’re all studying the elephant, or so we say, but we might easily mistake the trunk for a spear, or the tail for a rope, and so forth.
I want to see the whole elephant! Don’t you?
This painting of the Tower of Babel should remind all of us often we’re like the builders after suffering God’s wrath: Too often we struggle to communicate with one another about essential concepts and ideas from our distinct subfields.
For example, William James may have said that ‘everyone knows what attention is’, but I’m not sure we agree.
Relatedly, but perhaps less widely appreciated, the phenomena we study have a complex nested structure.
I designed this logo for my lab group to remind me of it.
The science of the mind and behavior collects and integrates evidence from at least four logically separable but mutually embedded realms.
Body (\(B\) ) within world (\(W\) )
Nervous system (\(N\) ) within body (\(B\) )
Mind (\(M\) ) within nervous system (\(N\) )
Our bodies are embedded in a world. Our nervous systems with our bodies. And our mind within the nervous system.
\(\dot{M} = f(M,N)\)
\(\dot{N} = f(N,B)\)
\(\dot{B} = f(B,N,W)\)
\(\dot{W} = f(W,B)\)
And using the mathematical language of dynamical systems, we can say that these realms are mutually coupled to one another: Changes in the mind are a function of mental and nervous system states, and so forth…
And make no mistake: The mind, brain, and body are non-linear dynamical systems, whether or not we study them that way.
Dynamical systems involve rule-based changes in state variables.
\(W\) , \(B\) , \(N\) more or less directly
States of the world, the body, and the nervous system can be measured more or less directly…
Sejnowski, Churchland, & Movshon, 2014
…across multiple spatial & temporal scales. This figure from Sejnowski et al. shows how the neuroscientist’s toolkit has expanded substantially over the last several decades.
I believe that JSMF support has contributed to this growth.
Measure mental states \(M\) indirectly
Via \(N\) , \(B\) , \(W\) (+ prior beliefs/knowledge)
But unfortunately, while often the star of the psychological show, we can only measure mental states indirectly via the nervous system, or changes in body state or behavior, and informed by prior beliefs and knowledge about those states.
I think these differences in measurement have consequences for inference we have yet to confront fully.
Beyond challenges in measurement, we may not appreciate the structure of the theoretical frameworks that dominate our scientific discourse.
I’ve recently become interested in some of the intellectual ancestors to cognitive science that we seem to have abandoned along the way: cybernetics and control theory are among them.
Linear/open-loop theoretical frameworks dominate
In the language of these fields, linear/open-loop theoretical frameworks dominate psychological science.
B.F. Skinner
Consider the S-R psychology of the behaviorists, best epitomized by B.F. Skinner.
\(Stimulus (S) \rightarrow Response (R)\)
Behaviorism attempted to show how all observable behavior could be determined by understanding the links between stimuli and responses.
Noam Chomsky
\(Stimulus (S) \rightarrow Cognition (C) \rightarrow Response (R)\)
Here significant, essential processing (cognition or computation) intervene between stimulus and response.
\(S \rightarrow N \leftrightarrow C \rightarrow R\)
that brings to bear evidence about the computing hardware to understanding the operation of the mind’s software.
Make no mistake, I view this progression of ideas as advancing our understanding of the mind and brain.
Closed-loop causal chains better reflect the underlying reality
But I also think that the underlying reality is more complex than this, and that non-linear, closed-loop, causal chains better reflect what cognitive science is really about.
The reality is that responses affect the world, responses and world states evoke stimuli, stimuli affects cognition, cognition affects responses, and the cycle repeats.
Non-linear, closed-loop dynamical systems like this require broader and denser data about all of the realms in order to reveal the underlying processes. Data that can be difficult or expensive to collect.
But even in situations when the data are available, when all of these states are well-known, our current methods have some striking limitations.
Jonas & Kording 2017
A recent paper by Jonas and Kording illustrates this point. These authors used conventional neuroscience techniques – studying the connection pattern, observing the effects of damage on performance, responses of individual components to simulate ‘recording’ from a microprocessor that was engaged in the inputs and outputs of several well-known video games. So, in effect, they already ‘knew’ the answers they were looking for.
What did they find?
“We show that [classic analytic neuroscience] approaches reveal interesting structure in the data… ”
Jonas & Kording 2017
“…but do not meaningfully describe the hierarchy of information processing in the microprocessor. ”
Jonas & Kording 2017
“This suggests current analytic approaches in neuroscience may fall short of producing meaningful understanding of neural systems, regardless of the amount of data. ”
Jonas & Kording 2017
So, while there are many questions in cognitive science and neuroscience where more data are essential, bigger data aren’t enough.
Moreover, there are reasons to think we may need to broaden our approach to information processing.
The Turing machine as a universal computational device is the dominant framework in computer science, and most cognitive scientists think (explicitly or not) that the mind is some sort of computational device.
Central to this way of thinking is the goal of cognitive science is to reveal the algorithms or recipe for evaluating and transforming data.
We don’t have to look very far to see how powerful and widespread algorithms have become in our day-to-day life.
CC BY-SA 3.0 , Link
But algorithms aren’t the only useful ways to transform information.
This is the steam engine designed by James Watt in the late 1700s. It helped launch the industrial age.
How to regulate the speed of a Watt-style steam engine?
And like most powerful and useful machines, it has to be controlled to be useful. Beyond turning it on and off, the most important control is speed. How to keep the speed constant?
1. Measure the speed of the flywheel.
2. Compare the actual speed against the desired speed.
3. If there is no discrepancy, return to step 1. Otherwise,
a. measure the current steam pressure;
b. calculate the desired alteration in steam pressure;
c. calculate the necessary throttle valve adjustment.
4. Make the throttle valve adjustment.
5. Return to step 1.
To a 21st century audience steeped in algorithmic thinking and surrounded by computational devices, the answer is obvious: Measure the speed, compare it to some desired value, if it differs, adjust the steam valve up or downward.
This is a negative feedback loop of the sort we’re familiar with in various contexts, from thermostats to cruise control in our cars.
Note that the algorithm presumes that there are variables we can measure – like speed, and calculations we can quickly and accurately.
The real world solution Watt devised was mechanical and of a completely different form. Cheap sensors hadn’t been invented yet. All calculation was done by humans, not machines. Watt’s solution took advantage of the interactions of mechanical elements, rotational and gravitational forces.
I thank Tim Van Gelder for persuasively arguing that a strictly information processing/computational approach pushes us to seek out algorithms when systems that exploit intrinsic dynamics of the materials might more useful or appropriate.
“If all you have is a hammer, everything looks like a nail.” (Maslow)
How much do we really understand about biological computing?
The implication is that we may see computational devices everywhere because they are ubiquitous in the environments we have created.
But does this necessarily mean that biological entities work this way or in all cases? How much do we really understand about how biological entities compute?
Constrained by space, time, energy
25 W vs. ?? MW
This photo shows Google’s AI system, AlphaGo in the midst of defeating the World Champion Go player. Considering that Go was thought far too difficult a game for computers to master, it’s indeed an achievement.
But the human player’s brain was using about 25 W. I don’t know that Google has revealed AlphaGo’s power consumption in doing the same task, but it was probably in the megawatts.
So we’re a long way from developing computational systems that are as energy efficient as brains.
Computes with chemistry (neurotransmitters, hormones) when possible
With ‘wires’ (axons & dendrites) when necessary
One reason for this may be that biological computing seems to involve chemistry whenever possible, and wires only when necessary.
Peter Sterling and Simon Laughlin discuss the implications of this in their book Neural Computing.
I think it’s safe to say that we don’t yet appreciate the implications of this sort of hybrid computing architecture.
Engages in real-time behaviors with existential consequences (e.g., ingestion, defense, reproduction, locomotion, pursuit)
Operates effectively in complex, dynamic environments
Big data (-omics) initiatives in the biological sciences…
…largely overlook behavior
For example, other areas of biomedicine have taken ‘big data’ approaches to revealing the structure at different levels of spatial and temporal resoulution.
The oversight is slowly gaining recognition in neuroscience, as indicated by this recent paper by Krakauer and colleagues.
Krakauer and colleagues question whether the behaviors we study are truly representative, whether there is a one-to-one relationship between brain systems and those behaviors, and so on.
“Behavior is the linchpin of the most vexing problems in public health… ”
Gilmore, Adolph, & Tamis-LeMonda, 2019
My colleagues and I have argued that behavior is the linchpin of the most vexing problems in public health.
“Behavior contributes to the progression or prevention of disease, defines a disorder or marks recovery, and provides mechanisms for therapeutic intervention. ”
Gilmore, Adolph, & Tamis-LeMonda, 2019
That behavior contributes to the progression or prevention of disease, defines a disorder or marks recovery, and provides mechanisms for therapeutic intervention.
“…a better understanding of behavior is fundamental to achieving positive health outcomes, from prenatal development throughout adulthood. ”
Gilmore, Adolph, & Tamis-LeMonda, 2019
And that a better understanding of behavior is fundamental to achieving positive health outcomes, from prenatal development throughout adulthood.
I’d extend these claims to the principal task of understanding human cognition.
So psychology and allied fields are harder than physics for many reasons.
But there is an additional challenge that all sciences face: The challenge of producing reliable, robust, generalizable findings.
Richard Harris’ book, Rigor Mortis, exposes some shocking problems with reproducibility in biomedical research, and I urge you to read it.
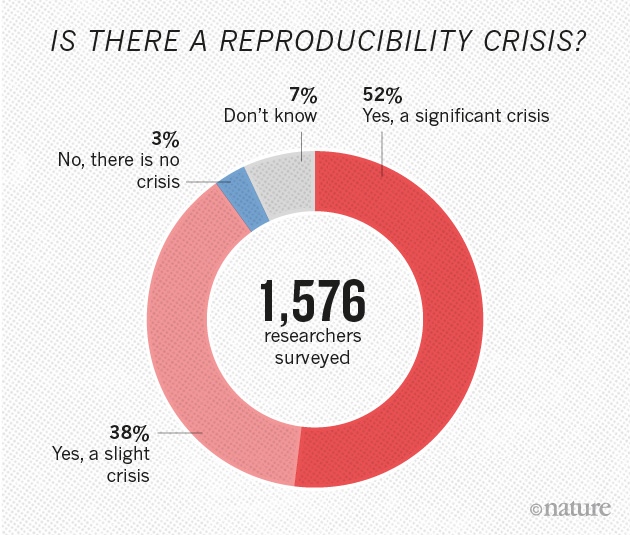
Is there a reproducibility crisis in science?
But let’s start with a question: Is there a reproducibility crisis in science?
Nature asked scientists across fields this question in 2016.
Let’s focus on psychological science.
Yes, a significant crisis
Yes, a slight crisis
No crisis
Don’t know
So, how many of you think there is a significant crisis in psychological science? A slight crisis? No crisis? Don’t know.
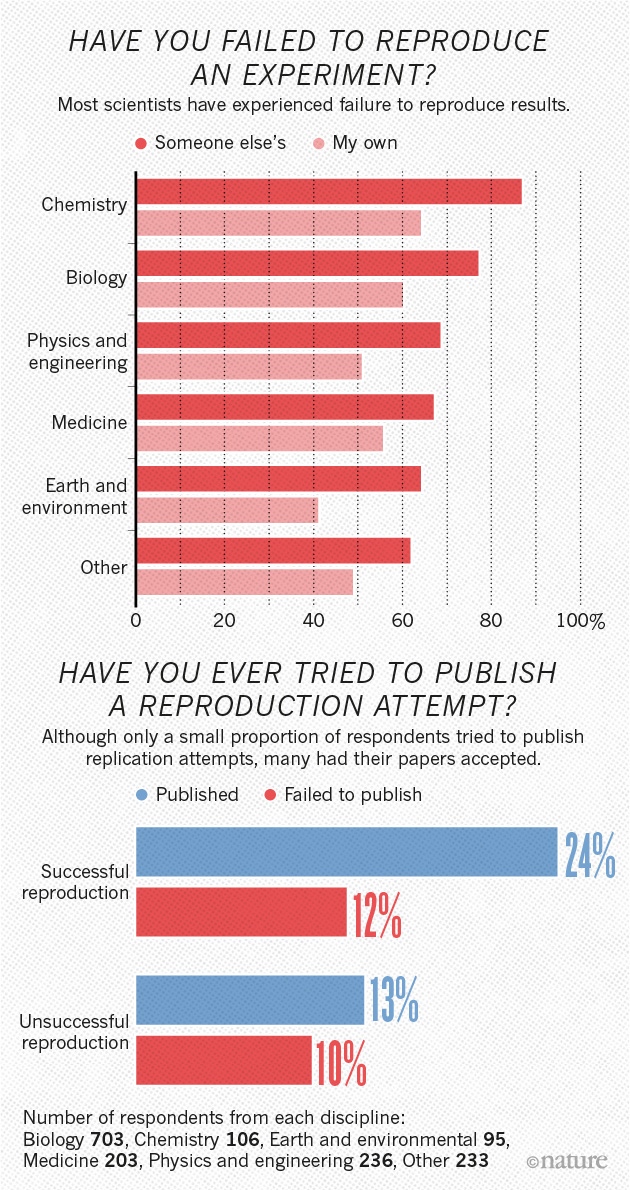
Have you failed to reproduce an experiment from your lab or someone else’s?
Nature asked a second question you can think about yourself.
I think the results are especially interesting.
Look at the fields where the highest levels of failures to replicate are reported: chemistry, biology, physics & engineering, earth and mineral sciences. The so-called ‘hard’ sciences.
I’m not sure, but I think psychology and the social sciences fall into ‘other’. See, we’re not doing so badly!
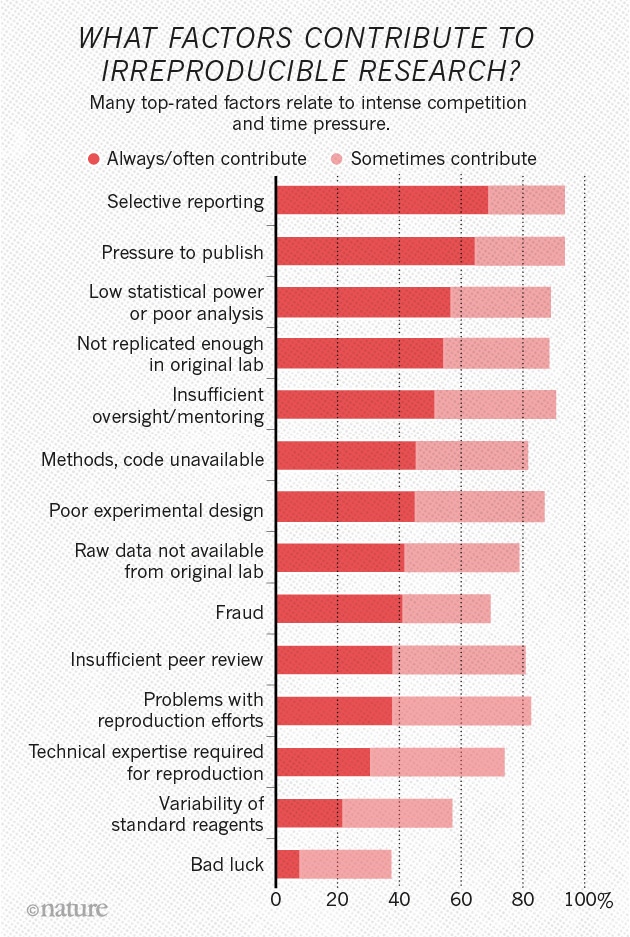
We won’t dwell on the factors that respondents said contribute to these problems, but I think they are by now familiar.
And I’m greatly encouraged by the attention and energy psychologists are giving to how to improve research methodology and inference.
One area where I think we could spend a bit more energy concerns the role of theory, and for this, I thank George Mischel for giving the problem a clever name: the toothbrush problem.
“…psychologists tend to treat other peoples’ theories like toothbrushes; no self-respecting individual wants to use anyone else’s. ”
Mischel, 2009
“The toothbrush culture undermines the building of a genuinely cumulative science, encouraging more parallel play and solo game playing, rather than building on each other’s directly relevant best work. ”
Mischel, 2009
Do we want to build a ‘genuinely cumulative science’?
I do, and I think you do, too.
So what do we need to do?
[RIGHT]
Making cognitive science even better
studies behavior(s)
not just (difficult-to-measure-directly) internal states
Powers 1973
Bill Powers work on perceptual control theory seems to have left little mark on psychology, but this figure from his 1973 book I find instructive.
It shows how one might decompose a simple object tracking task into a series of perception/computation/action loops.
This particular model may or may not be the right one. But we could and should have much richer descriptions of and theories about behaviors that can be rigorously tested.
samples densely (and/or broadly) in time & space
creates meaningful linkages across levels of analysis
I also recommend that sponsors support research that samples densely or broadly in time & space and strives to achieve meaningful linkages across levels of analysis.
As this figure from Bronfenbrenner depicts, psychologists, especially those with training in development have long understood that a satisfying understanding of human behavior requires understanding influences within the individual and outside her.
In neuroscience, the tools of network theory have come to play important roles in inference.
And network theory is a powerful tool that will help cognitive scientists characterize the networks of factors that influence human computation.
is informed by rich theories of task performance (inputs, controlled variables, outputs)
attempts to close causal loops
Psychologists seem to shun discussions of causality.
But there has been lively and active progress in developing ways to test causal relationship statistically. And progress would be accelerated if we were comfortable put our necks out to specify and test causal models.
resists “premature simplification”
Matejka & Fitzmaurice
These data (the Datasaurus dozen) are a version of Anscome’s Quartet known to statistics for a long time. All of the distributions have the same means in X and Y, the same standard deviations, and the same correlations. If we didn’t visualize the data, and took as a given the simplification provided by the summary statistics, we’d miss important details.
Dimension reduction or simplification is essential in science, but only when it adds to our understanding and doesn’t discard something essential.
The challenge is knowing when it’s safe to simplify and when it’s not.
Powers 1973
This figure from Bill Powers again shows a later, more complex version of the same visual object tracking task. Here the more complicated model explains more aspects of behavior.
I suggest that cognitive science can and should probably complicate before we simplify.
demonstrates a meaningful commitment to producing rigorous, reproducible, & robust findings
I also recommend providing support for research that demonstrates a meaningful commitment to producing rigorous, reproducible, & robust findings.
That is, findings we can bank on.
This recent book by Deborah Mayo argues that whatever statistical framework we adopt, the common goal ought to be to rigorously test scientific claims with only the strongest surviving the tests.
Support research that
In that spirit, I recommend that sponsors support research…
collects & shares video as data & documentation
For starters, my colleagues and I have argued that the more widespread use of video for both purposes will improve psychological science.
Video…
Captures (& preserves) behavior
Shows (& helps tell…)
Expands the scope of inquiry
Provides unequaled opportunities for reuse
Your browser does not support the video tag.
We’re putting these claims to a very public test through the Play & Learning Across a Year (PLAY) project.
PLAY is collecting video recordings of mothers and infants engaged in natural activity in the home.
Human observers will add time-locked annotations of speech, language, and gesture, locomotion and physical activity, object interaction, and emotion.
\(n=900\) 12-, 18-, 24-mo-olds; \(n=30\) sites demographics, health, vocabulary, media use, & temperament openly shared with the research community play-project.org
The coded videos plus parent-report information will be openly shared with the research community via Databrary.
Support research that
Shares procedures, materials, code, & data openly (but securely)
To build on the substantial progress psychological science is making in terms of reproducibility, I recommend supporting research that shares procedures, materials, code, & data openly (but securely).
For PLAY, that means a completely open protocol, including coding definitions, item-level survey information, and so on.
Makes sharing scripted, fully reproducible workflows easy
Sponsors should also support research that makes it easy for others to validate findings by creating scripted, fully reproducible workflows.
Tamis-LeMonda 2014
Here’s an example, let’s say you want to explore building upon Catherine Tamis-LeMonda’s shared dataset. It’s one of the largest and most diverse.
vol_8 <- databraryapi::download_session_csv(vol_id = 8)
vol_8 %>%
filter(participant.gender %in% c('Male', 'Female')) %>%
ggplot() +
aes(x = participant.race, fill = participant.race) +
facet_grid(. ~ participant.gender) +
geom_bar(stat="count") +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
This small fragment of code from the R programming language downloads demographic data from Cathie’s dataset and produces this summary plot.
The same code will work on another person’s computer because the data come from Databrary, not from C:\my-research-data\cathie-project
Support research that
Finally, I recommend that sponsors support research that
enables linkages between & across data sets
exploits advances in AI and machine learning
Your browser does not support the video tag.
Source: Ori Ossmy, NYU
The video shows the output of an open source computer vision algorithm called OpenPose run on a video of a child playing in a laboratory setting. These tools promise to accelerate the annotation of video.
Linda Smith and Chen Yu have been pursuing similar efforts in their own work.
Ossmy, Gilmore, & Adolph 2019
In our work with Ori Ossmy, we’ve shown that computer vision techniques can be 100 times faster than human coders and with similar levels of precision.
The human cost of video annotation is one of the biggest barriers to its widespread use, and so the potential to reduce these substantially is tremedously exciting.
If we do these things…
In summary, if we do these things…
## R version 3.5.2 (2018-12-20)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS Mojave 10.14.5
##
## Matrix products: default
## BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] igraph_1.2.2 forcats_0.3.0
## [3] stringr_1.4.0 dplyr_0.8.0.1
## [5] purrr_0.3.2 readr_1.3.1
## [7] tidyr_0.8.2 tibble_2.1.1
## [9] ggplot2_3.1.0 tidyverse_1.2.1
## [11] databraryapi_0.1.6.9001
##
## loaded via a namespace (and not attached):
## [1] revealjs_0.9 tidyselect_0.2.5 xfun_0.6 reshape2_1.4.3
## [5] haven_2.0.0 lattice_0.20-38 colorspace_1.4-1 generics_0.0.2
## [9] htmltools_0.3.6 yaml_2.2.0 rlang_0.3.3 pillar_1.3.1
## [13] glue_1.3.1 withr_2.1.2 modelr_0.1.2 readxl_1.2.0
## [17] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0
## [21] rvest_0.3.2 codetools_0.2-15 evaluate_0.13 labeling_0.3
## [25] knitr_1.22 curl_3.3 highr_0.8 broom_0.5.1
## [29] Rcpp_1.0.1 scales_1.0.0 backports_1.1.3 jsonlite_1.6
## [33] hms_0.4.2 digest_0.6.18 stringi_1.4.3 keyring_1.1.0
## [37] grid_3.5.2 cli_1.1.0 tools_3.5.2 magrittr_1.5
## [41] lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2 rsconnect_0.8.13
## [45] xml2_1.2.0 lubridate_1.7.4 assertthat_0.2.1 rmarkdown_1.12
## [49] httr_1.4.0 rstudioapi_0.10 R6_2.4.0 nlme_3.1-137
## [53] compiler_3.5.2











_-_Google_Art_Project.jpg#/media/File:Pieter_Bruegel_the_Elder_-_The_Tower_of_Babel_(Vienna)_-_Google_Art_Project.jpg)